Как масштабировать семантическое ядро в сезон? И получить лиды по 1000 рублей с НДС
Пошаговая инструкция для всех!
Стояла задача масштабировать семантическое ядро. Как это реализовали? Ответ на этот вопрос читайте в данной статье.
Для начала определимся с нишей, которую будем использовать для примера. Пусть это будет установка пластиковых окон. Важно понимать, что сервис Wordstat выдает нам результат за предыдущие 30 дней.
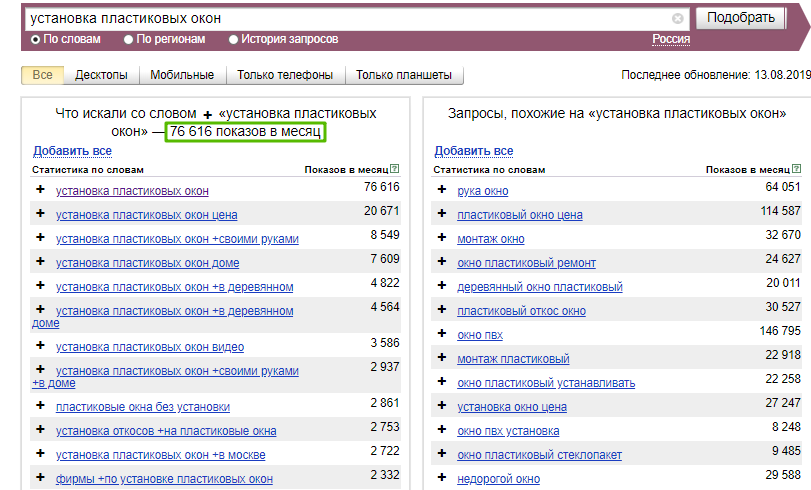
Время моего сбора семантики — середина августа и по данным за предыдущий год идет самый разгар сезона.
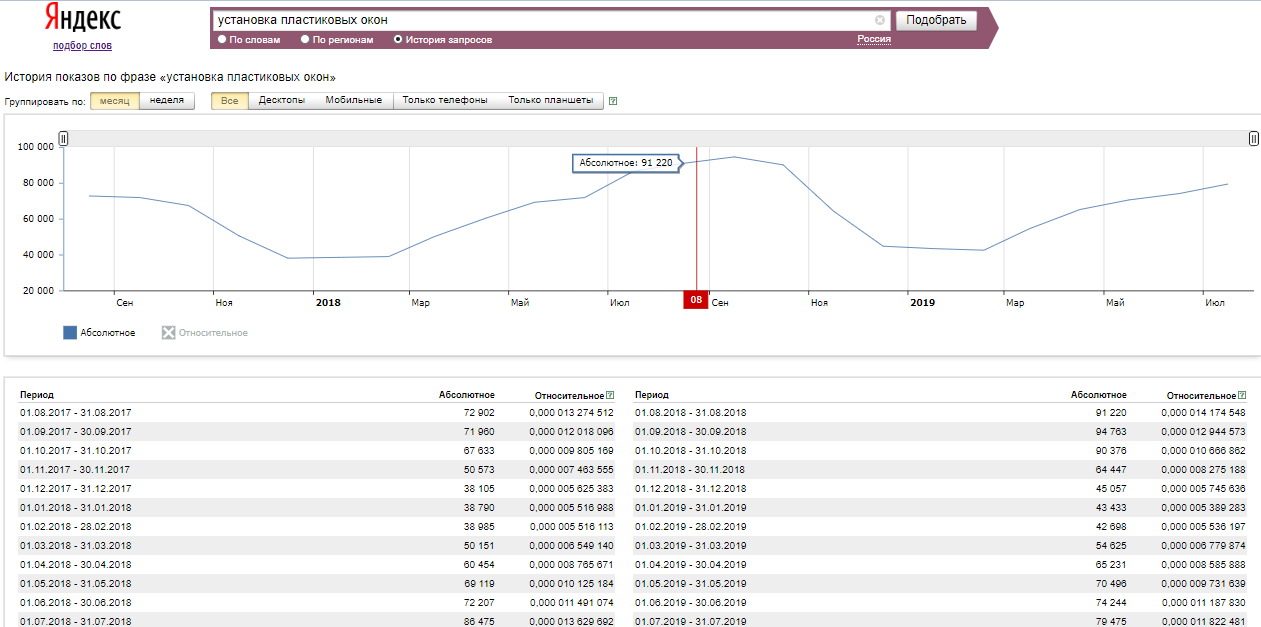
Вместе с этим можно заметить, что с марта идёт рост поисковых запросов, соответственно собирая данные в несезон, мы теряем часть запросов, по которым могут быть показы наших рекламных объявлений.
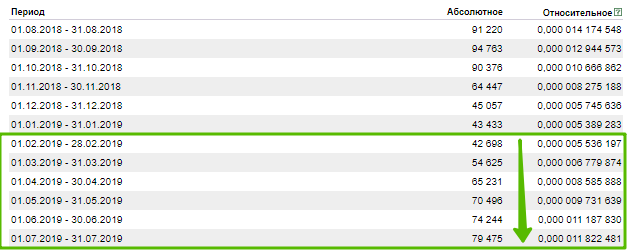
Итак: мы собрали РК в декабре, загрузили их в яндекс, запустили и решили дособрать семантику в августе с учетом новых данных. Нужно снова собрать все ключи и как-то исключить те, которые уже есть в наших рекламных кампаниях.
Для этого нам понадобились:
маски, по которым мы собирали семантику;
собранная семантика;
любой парсер типа key collector;
Маска – это вч (высокочастотный) ключ, по которому собираются все вложенные в него запросы. У нас это “установка пластиковых окон”.
Заходим в key collector. Я заранее подготовил файл, по которому мы производили сбор зимой. Вы можете выгрузить семантику из интерфейса директа и загрузить в коллектор самостоятельно, далее распишу для чего…
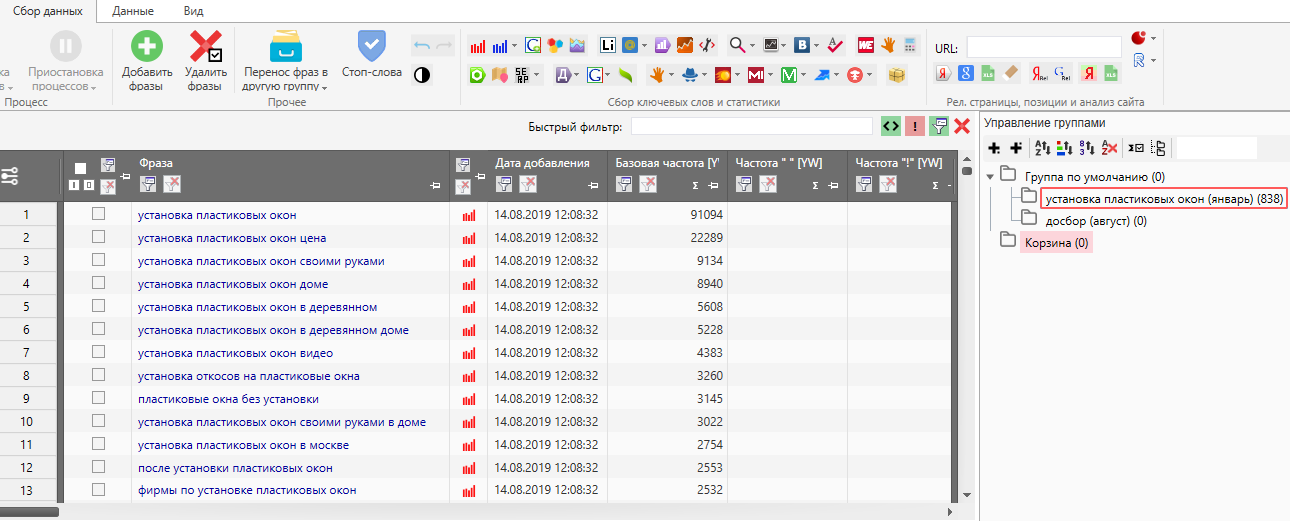
У нас получилось зимой порядка 800 ключей, далее выбираем папку досбор (август):
Нажимаем пакетный сбор из левой колонки яндекса;
Появляется окно настройки сборщика;
Ставим галочку «не добавлять фразу, если она уже есть в любой другой группе;
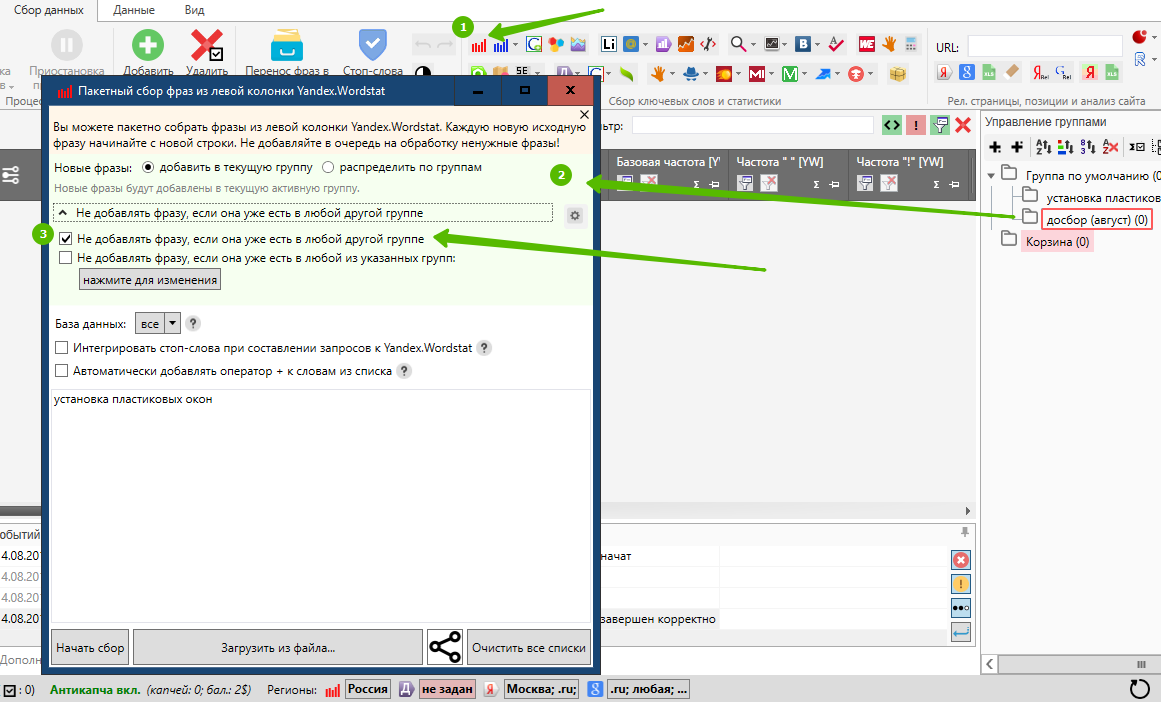
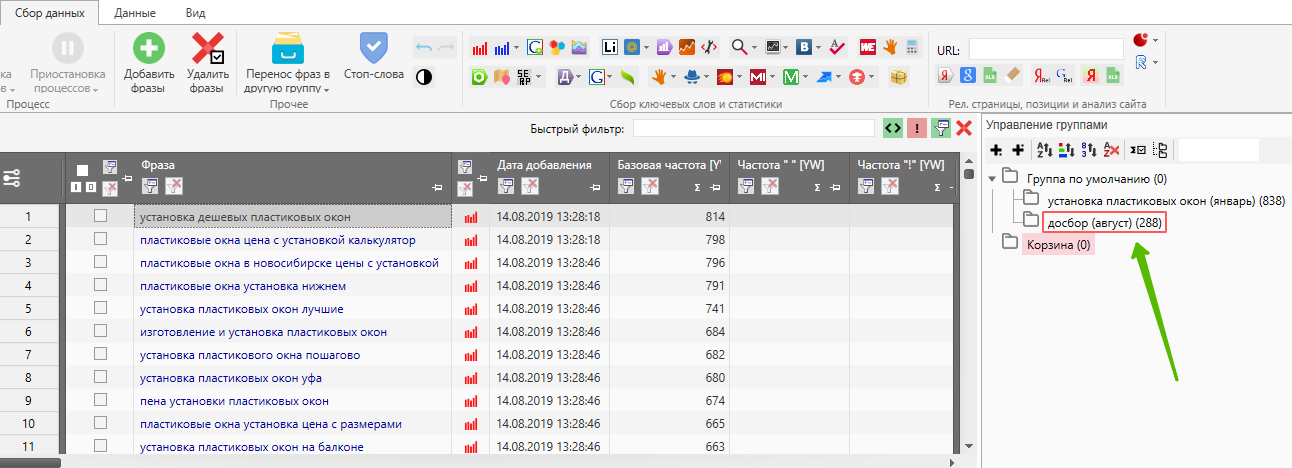
Итого мы собрали дополнительные 200 ключей, которые добавили к нашей РК.
 Похожие темы
Похожие темы





 Линейный вид
Линейный вид

